Excel Analysis
Verifiedby davila7 · Updated Apr 16, 2026
Analyze Excel spreadsheets, create pivot tables, generate charts, and perform data analysis. Use when analyzing Excel files, spreadsheets, tabular data, or .xlsx files.
See It In Action
Let me find the Excel file and understand the data first.
Found pipeline_workbook.xlsx. Let me invoke the Excel analysis skill to work with it.
Let me start by reading the workbook to understand the data.
The default python3 is in a venv without pandas. Let me use the conda environment.
Good. Now I can see the issues clearly:
- Duplicate rows: rows 6/8 (D-1002), rows 4/11 (D-1004), rows 2/7 (D-1003), rows 9/10 (D-1005)
- Inconsistent stages: "proposal"/"PROPOSAL", "Discovery"/"Disco", "PROSPECTING"/"Prospect", "CLOSED WON"/"Closed-Won", "NEGOTIATION"
I also need to figure out the region dimension. Let me check if there's a second sheet or if region needs to be derived from Rep.
Now I have the full picture — 4 regional sheets, each with duplicates and messy stage names. Let me build the cleaned workbook.
Hmm, conda run seems to suppress output. Let me try differently.
Let me verify the chart and output file look good.
All done. Here's what was cleaned up and produced:
Cleanup Summary
| Issue | Before | After |
|---|---|---|
| Total rows | 50 (across 4 sheets) | 34 (16 dupes removed) |
| Stage variants | 17 inconsistent labels (Disco, Neg, PROPOSAL, Closed-Won, PROSPECTING, etc.) | 6 clean stages |
| Duplicates | Same Deal_ID appearing multiple times per region with different stage spellings or exact copies | 1 row per deal per region, keeping the most advanced stage |
Stage Normalization Applied
Disco/Discovery/discovery → Discovery, Prop/proposal/PROPOSAL → Proposal, Neg/Negotiating/negotiation/NEGOTIATION → Negotiation, Prospect/PROSPECTING/prospecting → Prospecting, Closed-Won/closed won/CLOSED WON → Closed Won, Lost/Closed-Lost/Closed Lost → Closed Lost
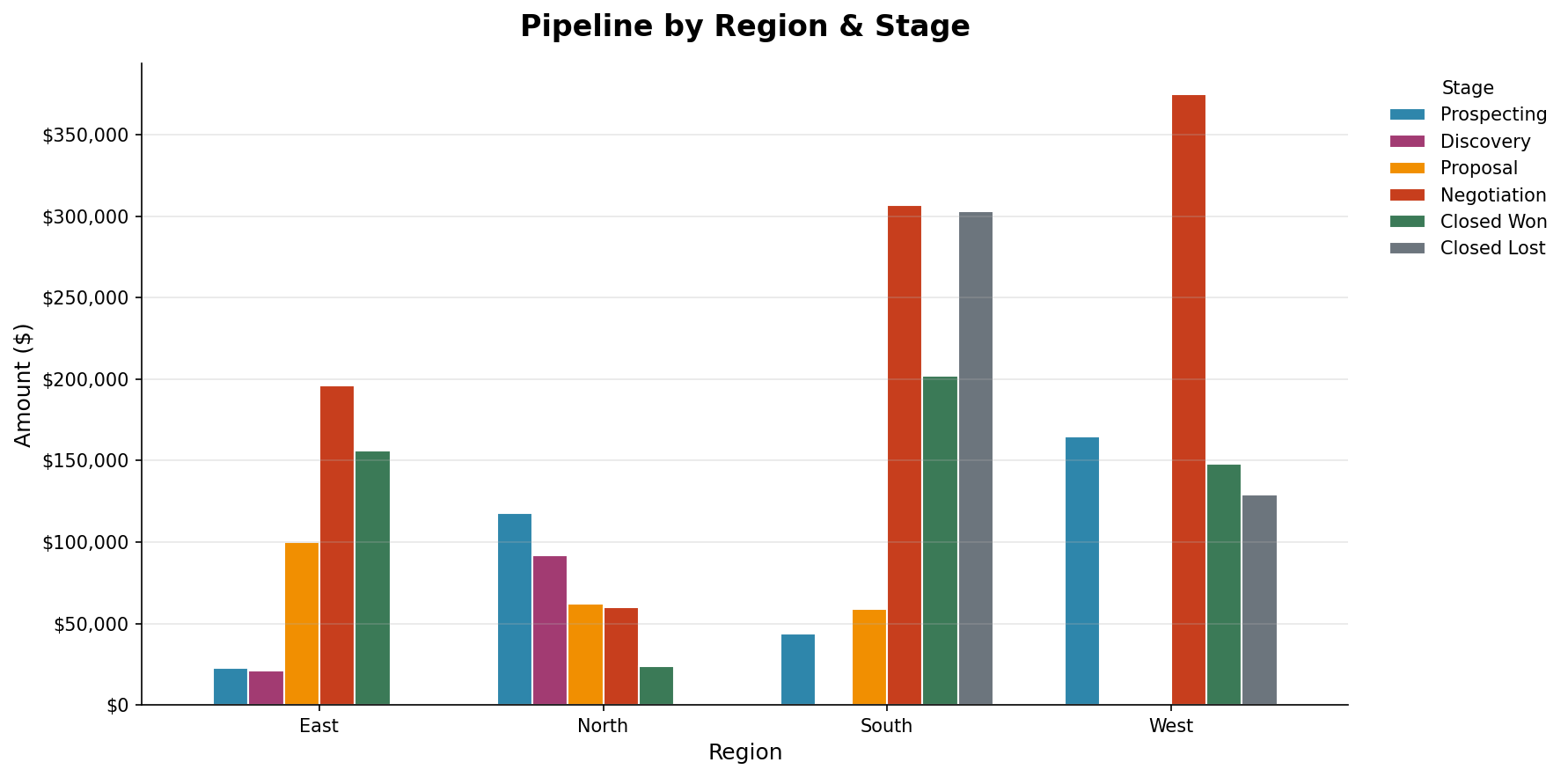
Region x Stage Summary ($)
| Region | Prospecting | Discovery | Proposal | Negotiation | Closed Won | Closed Lost | Total |
|---|---|---|---|---|---|---|---|
| East | $23K | $21K | $100K | $196K | $156K | $0 | $496K |
| North | $118K | $92K | $62K | $60K | $24K | $0 | $356K |
| South | $44K | $0 | $59K | $307K | $202K | $303K | $915K |
| West | $165K | $0 | $0 | $375K | $148K | $129K | $817K |
| Grand Total | $350K | $113K | $221K | $938K | $530K | $432K | $2.58M |
Output Files
pipeline_workbook_clean.xlsx— 2 sheets: "Pipeline Data" (cleaned deal rows with Region column) + "Region x Stage Summary" (pivot with totals), formatted with headers, currency, and auto-sized columnspipeline_region_stage_chart.png— grouped bar chart of pipeline amount by region and stage
Ready for the 3pm review.
External Tools
| Tool | Type |
|---|---|
| python3 | binary |
Permissions
| Scope | Description |
|---|---|
| filesystem:read | |
| filesystem:write | |
| process:spawn |
SKILL.md
Excel Analysis
Quick start
Read Excel files with pandas:
import pandas as pd
# Read Excel file
df = pd.read_excel("data.xlsx", sheet_name="Sheet1")
# Display first few rows
print(df.head())
# Basic statistics
print(df.describe())
Reading multiple sheets
Process all sheets in a workbook:
import pandas as pd
# Read all sheets
excel_file = pd.ExcelFile("workbook.xlsx")
for sheet_name in excel_file.sheet_names:
df = pd.read_excel(excel_file, sheet_name=sheet_name)
print(f"\n{sheet_name}:")
print(df.head())
Data analysis
Perform common analysis tasks:
import pandas as pd
df = pd.read_excel("sales.xlsx")
# Group by and aggregate
sales_by_region = df.groupby("region")["sales"].sum()
print(sales_by_region)
# Filter data
high_sales = df[df["sales"] > 10000]
# Calculate metrics
df["profit_margin"] = (df["revenue"] - df["cost"]) / df["revenue"]
# Sort by column
df_sorted = df.sort_values("sales", ascending=False)
Creating Excel files
Write data to Excel with formatting:
import pandas as pd
df = pd.DataFrame({
"Product": ["A", "B", "C"],
"Sales": [100, 200, 150],
"Profit": [20, 40, 30]
})
# Write to Excel
writer = pd.ExcelWriter("output.xlsx", engine="openpyxl")
df.to_excel(writer, sheet_name="Sales", index=False)
# Get worksheet for formatting
worksheet = writer.sheets["Sales"]
# Auto-adjust column widths
for column in worksheet.columns:
max_length = 0
column_letter = column[0].column_letter
for cell in column:
if len(str(cell.value)) > max_length:
max_length = len(str(cell.value))
worksheet.column_dimensions[column_letter].width = max_length + 2
writer.close()
Pivot tables
Create pivot tables programmatically:
import pandas as pd
df = pd.read_excel("sales_data.xlsx")
# Create pivot table
pivot = pd.pivot_table(
df,
values="sales",
index="region",
columns="product",
aggfunc="sum",
fill_value=0
)
print(pivot)
# Save pivot table
pivot.to_excel("pivot_report.xlsx")
Charts and visualization
Generate charts from Excel data:
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_excel("data.xlsx")
# Create bar chart
df.plot(x="category", y="value", kind="bar")
plt.title("Sales by Category")
plt.xlabel("Category")
plt.ylabel("Sales")
plt.tight_layout()
plt.savefig("chart.png")
# Create pie chart
df.set_index("category")["value"].plot(kind="pie", autopct="%1.1f%%")
plt.title("Market Share")
plt.ylabel("")
plt.savefig("pie_chart.png")
Data cleaning
Clean and prepare Excel data:
import pandas as pd
df = pd.read_excel("messy_data.xlsx")
# Remove duplicates
df = df.drop_duplicates()
# Handle missing values
df = df.fillna(0) # or df.dropna()
# Remove whitespace
df["name"] = df["name"].str.strip()
# Convert data types
df["date"] = pd.to_datetime(df["date"])
df["amount"] = pd.to_numeric(df["amount"], errors="coerce")
# Save cleaned data
df.to_excel("cleaned_data.xlsx", index=False)
Merging and joining
Combine multiple Excel files:
import pandas as pd
# Read multiple files
df1 = pd.read_excel("sales_q1.xlsx")
df2 = pd.read_excel("sales_q2.xlsx")
# Concatenate vertically
combined = pd.concat([df1, df2], ignore_index=True)
# Merge on common column
customers = pd.read_excel("customers.xlsx")
sales = pd.read_excel("sales.xlsx")
merged = pd.merge(sales, customers, on="customer_id", how="left")
merged.to_excel("merged_data.xlsx", index=False)
Advanced formatting
Apply conditional formatting and styles:
import pandas as pd
from openpyxl import load_workbook
from openpyxl.styles import PatternFill, Font
# Create Excel file
df = pd.DataFrame({
"Product": ["A", "B", "C"],
"Sales": [100, 200, 150]
})
df.to_excel("formatted.xlsx", index=False)
# Load workbook for formatting
wb = load_workbook("formatted.xlsx")
ws = wb.active
# Apply conditional formatting
red_fill = PatternFill(start_color="FF0000", end_color="FF0000", fill_type="solid")
green_fill = PatternFill(start_color="00FF00", end_color="00FF00", fill_type="solid")
for row in range(2, len(df) + 2):
cell = ws[f"B{row}"]
if cell.value < 150:
cell.fill = red_fill
else:
cell.fill = green_fill
# Bold headers
for cell in ws[1]:
cell.font = Font(bold=True)
wb.save("formatted.xlsx")
Performance tips
- Use
read_excelwithusecolsto read specific columns only - Use
chunksizefor very large files - Consider using
engine='openpyxl'orengine='xlrd'based on file type - Use
dtypeparameter to specify column types for faster reading
Available packages
- pandas - Data analysis and manipulation (primary)
- openpyxl - Excel file creation and formatting
- xlrd - Reading older .xls files
- xlsxwriter - Advanced Excel writing capabilities
- matplotlib - Chart generation
FAQ
What does Excel Analysis do?
Analyze Excel spreadsheets, create pivot tables, generate charts, and perform data analysis. Use when analyzing Excel files, spreadsheets, tabular data, or .xlsx files.
When should I use Excel Analysis?
Use it when you need a repeatable workflow that produces image output, downloadable file.
What does Excel Analysis output?
In the evaluated run it produced image output, downloadable file.
How do I install or invoke Excel Analysis?
npx skills add https://github.com/davila7/claude-code-templates --skill excel-analysis
Which agents does Excel Analysis support?
Claude Code
What tools, channels, or permissions does Excel Analysis need?
It uses python3; channels commonly include image, file; permissions include filesystem:read, filesystem:write, process:spawn.
Is Excel Analysis safe to install?
Static analysis marked this skill as medium risk; review side effects and permissions before enabling it.
How is Excel Analysis different from an MCP or plugin?
A skill packages instructions and workflow conventions; tools, MCP servers, and plugins are dependencies the skill may call during execution.
Does Excel Analysis outperform not using a skill?
About Excel Analysis
When to use Excel Analysis
You need to inspect or summarize data from .xlsx or .xls spreadsheets. You want to clean, merge, or reshape Excel-based datasets. You need to generate pivot tables, formatted Excel outputs, or charts from spreadsheet data.
When Excel Analysis is not the right choice
You need live integration with cloud spreadsheet services like Google Sheets. You only need plain text or CSV processing without Excel-specific features.
What it produces
Produces image output and downloadable file.
Install
npx skills add https://github.com/davila7/claude-code-templates --skill excel-analysisInvoke: Ask Claude Code to use Excel Analysis for the task.